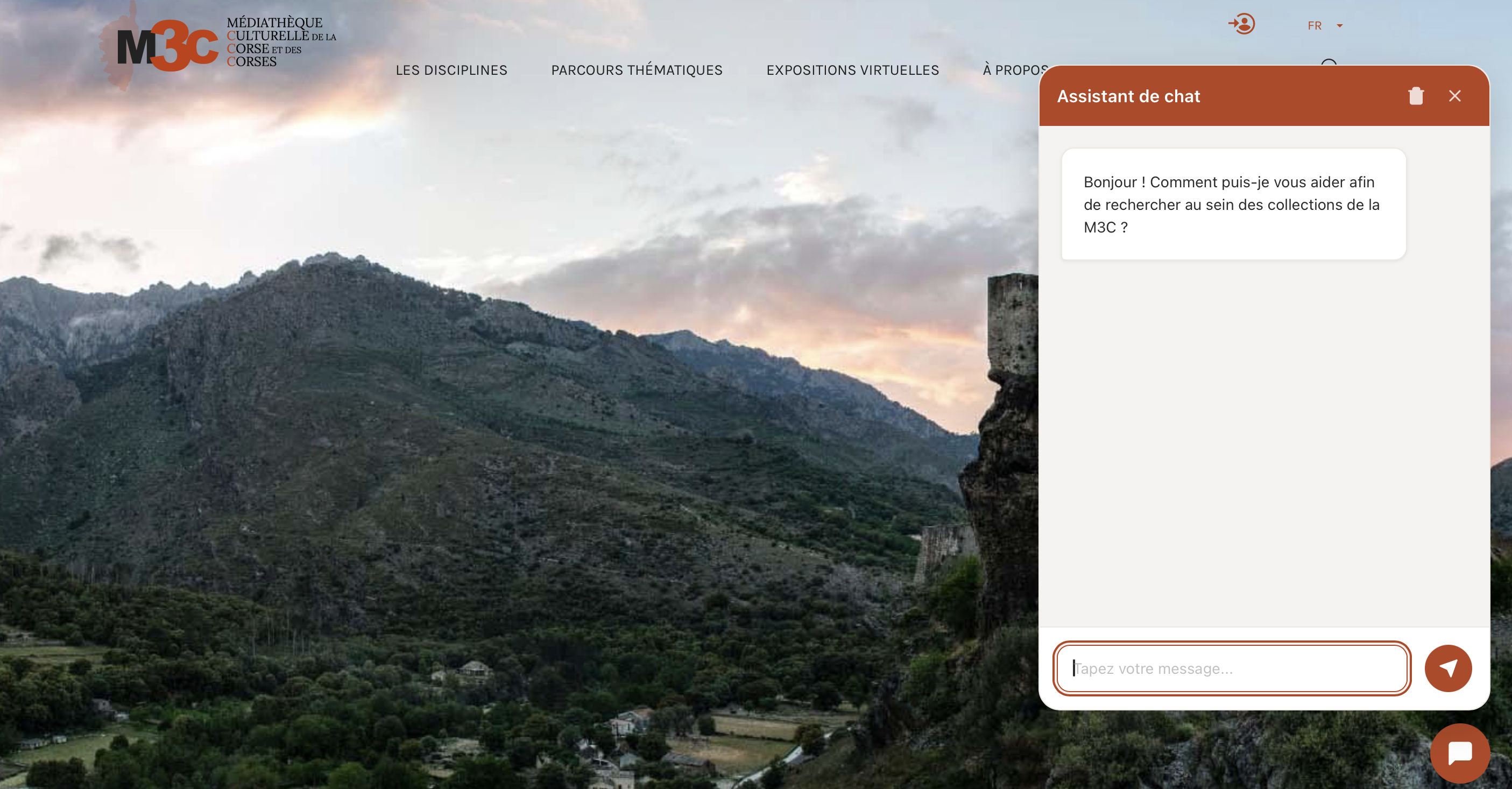


Limonad'IA vous donne accès à un environnement pré-configuré pour évaluer la recherche sémantique sur vos propres données patrimoniales — sans risque, sans infrastructure à gérer.
Omeka S structure et expose vos collections, mais la recherche par mots-clés atteint vite ses limites. Les usagers ne trouvent pas ce qu'ils cherchent vraiment, et le potentiel sémantique de vos métadonnées reste inexploité.
Les projets patrimoniaux hésitent à investir dans l'IA sans avoir pu en évaluer concrètement l'apport sur leurs propres données. Sans preuve sur votre corpus, difficile de convaincre en interne et de budgéter sereinement.
Limonad'IA est un POC as a Service clé en main — testez la recherche sémantique sur vos propres collections Omeka S, en 1 mois, sans rien installer.
Vos propres données dans un environnement sécurisé et dédié à votre projet.
L'apport réel de l'IA sur vos collections avant de prendre une décision d'investissement.
En connaissance de cause la suite de votre projet numérique patrimonial.
Import de votre dump Omeka S (versions 3 & 4) par notre équipe. Seules les métadonnées descriptives sont importées — aucun média, pour un transfert léger et sécurisé.
Paramétrage du module avec une configuration de base opérationnelle dès le départ. Vous choisissez votre modèle IA et adaptez les instructions à votre contexte.
Recherche sémantique sur vos collections, jusqu'à 1 000 requêtes par jour, avec un accès utilisateurs illimités pour impliquer toute votre équipe.
Un environnement isolé et sécurisé, exclusivement réservé à votre projet pendant toute la durée du POC.
Explorez vos données autrement qu'avec des mots-clés — la recherche sémantique comprend l'intention derrière la requête.
Gemma ou Qwen : deux modèles open source sélectionnés pour leur performance sur des corpus patrimoniaux.
Toute votre équipe peut tester simultanément, sans contrainte de licence ou de nombre de comptes.
Un quota généreux, conçu pour mener des sessions de tests intensifs et représentatifs de vos usages réels.
Import via dump Omeka S — aucun média, aucune donnée hors périmètre. Hébergement intégralement en France.
L'infrastructure IA est opérationnelle dès le premier jour. Aucune dépendance à un fournisseur propriétaire.
Sert deux types de modèles directement sur le serveur : un modèle d'embedding pour indexer vos données, un modèle de génération pour formuler les réponses. Aucune API externe, aucun envoi de vos données à un tiers. Souveraineté totale.
Stocke les représentations sémantiques de vos métadonnées produites par le modèle d'embedding. La recherche porte sur le sens des contenus, pas uniquement sur les mots-clés.
Deux modèles de génération open source au choix. Gemma (Google) et Qwen (Alibaba) sont optimisés pour la compréhension du langage naturel et la formulation de réponses précises sur des corpus spécialisés. Le modèle d'embedding associé est nomic-embed-text.
Analyse de la structure de vos données Omeka S pour maximiser la pertinence des résultats du chatbot.
Instructions personnalisées, modèle d'extraction des critères et modèle de génération de réponse adaptés à votre contexte métier.
Configuration avancée du module et réglage fin de l'indexation pour des recherches plus précises sur votre corpus spécifique.
Option payante — Tarif établi sur devis selon la complexité du projet et le volume de données à traiter.
À l'issue du mois de test, deux parcours s'offrent à vous selon votre contexte technique et vos ambitions.
Vous déployez le module Limonad'IA directement sur votre propre environnement Omeka S, avec la liberté de gérer votre hébergement IA.
Connectez votre module à notre infrastructure IA souveraine, sécurisée et entièrement maintenue par nos équipes.
Décrivez-nous votre projet. Nous revenons vers vous sous 48h pour organiser votre accès POC.
Vos données sont traitées conformément au RGPD et ne sont jamais partagées avec des tiers.